By Jyoti Prakash Singh
In the past, data platforms were simply stepping stones, a side project handled by your data team. Not any longer, as modern firms begin to see the true value of these platforms, treating them as production-grade software, or data-as-a-service. The resources dedicated to nurturing these platforms are no longer considered ancillary but absolutely crucial. A data platform is a consolidated repository and processing hub for all data within an organisation. It's responsible for gathering, cleaning, transforming, and utilizing data to create valuable business insights. Companies that give priority to their data have found data platforms to be an effective method for collecting, operationalizing, and democratizing data on a large scale. The advent of data mesh architecture and the rise of data products have necessitated viewing the data platform as an integral engine for their development, management, exposure, and regulation.
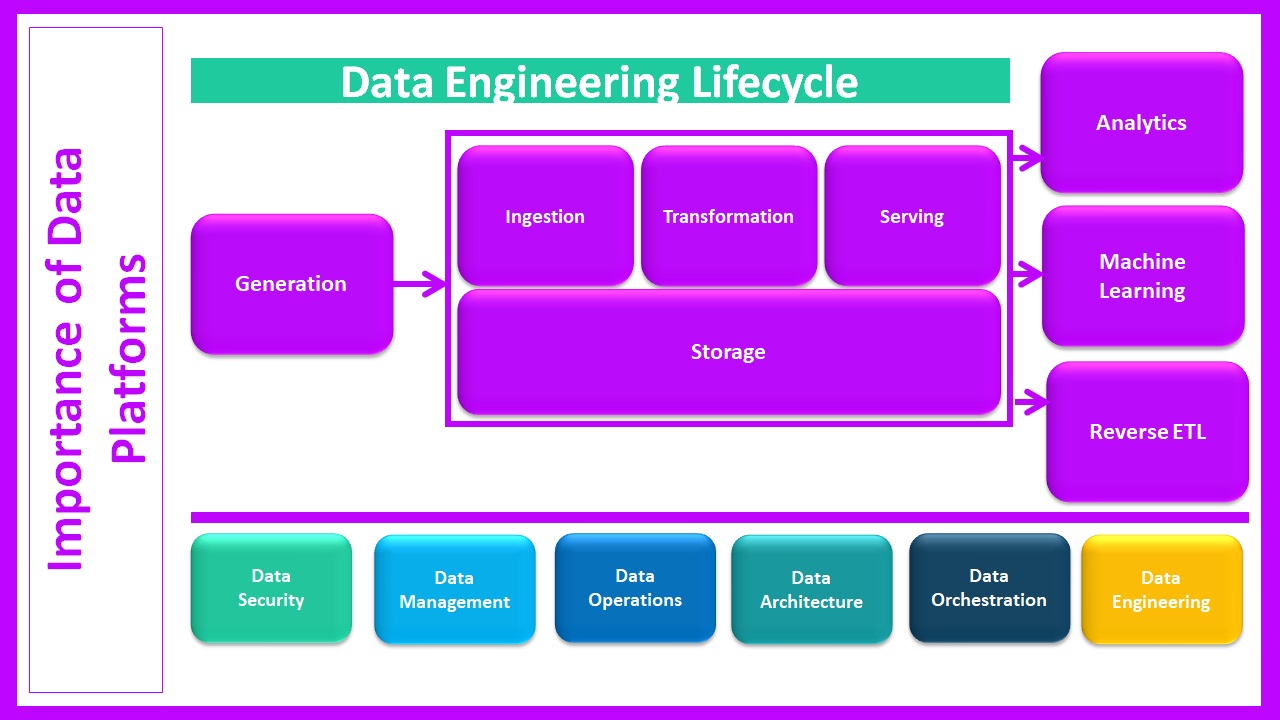
To simplify the process, below I have provided an outline of the essential layers that your data platform must contain, and in what order most superior teams opt to incorporate them. In light of recent developments, this post has been updated to account for added layers commonly present in a contemporary data platform, including data governance, access management, and machine learning.
1) Data storage and processing are critical parts of any modern-day business operation. When dealing with extensive data sets over extended durations, the need for a storage and processing layer becomes paramount. Coupled with the rise of businesses adapting to the cloud, there's a new dominant force in town - cloud-native solutions. They offer accessible, economical alternatives to many on-premise solutions, revolutionising data handling like never before. But, which option suits you – a data warehouse or a data lake, or perhaps a combination? The choice hinges upon your business prerequisites. Regardless of your preference though, you can't dream of a top-notch data platform without resorting to cloud storage and compute. Here's a peek into some leading options in the present cloud landscape:
2) Data ingestion essentially encapsulates the 'extraction and loading' stage seen in both Extract Transform Load (ETL) and Extract Load Transform (ELT) stages. It's where data structured or unstructured is migrated from diverse sources into a single, easily accessible system. This is the integration of data from one location to another without the use of data pipelines a key development in contemporary data management systems.There's no shortage of solutions for data ingestion in the market today. Here are a few remarkable solutions for batch data ingestion:
The following are the main players when it comes to data streaming ingestion:
Despite the abundance of tools, certain data teams opt to construct specialized code to facilitate data absorption from internal and external channels. This is where workflow automation and orchestration come in, featuring tools like Dagster, Apache Airflow, and Prefect. Far from merely ingesting the data, these systems merge isolated data with other resources, readying it for detailed analysis.
3) Data Transformation and Modeling are often regarded as synonymous, data transformation and data modeling significantly differ in their processes. While they share similarities, they have essential differences that distinguish one from the other. Data transformation is all about molding raw data into a more structured form. This can be achieved through implementing business logic. Data transformation makes data suitable for further analysis and reporting. It's a vital step in making data user-friendly and meaningful. Moving on to data modeling, it's a process that requires a clear vision. Data modeling involves devising a visual schema or framework for data, intending to store it in a data warehouse. It aids in understanding the intricate relationship among various data, making it easier to access and analyze.
The process of data transformation and data modeling isn't a simple one. It requires precision and proper tools. Let’s take a look at a few of them:
4) Business Intelligence and Analytics have been the game changers in the data world; they transform raw, complicated data into insightful, easy-to-understand information. They're the keys that unlock the door to the endless possibilities your data platforms hold. Imagine having a treasure chest full of valuable data, but no idea how to turn that raw bounty into useful information. Or being handed a fascinating book, but not understanding the language in which it is written. That's where Business Intelligence and analytics come in; they decode the data, making it meaningful and actionable. Business Intelligence (BI) and analytics serve as handy tools to mine, analyze, represent, and explain the data. They're the interface between raw data and the end-user, where the science of data meets the art of interpretation. By leveraging these tools, businesses can turn their information into answers. Here are some top-notch BI tools favored by data experts worldwide.
5) Data observability is a new-age approach businesses are adopting to fully understand their data status. It emphasizes the dependability and usability of ingested, stored, processed, analyzed, and transformed data. As enterprises become more data-reliant, and data pipelines grow intricate, the need for a flawless data environment is becoming inevitable. In essence, data observability refers to a company's ability to fully comprehend the status of the data within its data environment. This method brings in practices from DevOps, streamlining data pipelines to minimize data downtime and yield actionable outcomes. Here comes the role of five significant pillars of observability:
A data observability solution can smoothly associate with your existing data platform, creating a consistent, robust lineage that makes managing downstream dependencies effortless. Interestingly, this solution can also observe your stationary data, eliminating the requirement to extract the data from storage.
6) Data Orchestration is simply a strategic arrangement of multiple tasks into one end-to-end process. You are building data pipelines. All is good. But as soon as that data platform grows beyond a certain complexity level, controlling those operations becomes a nightmare. That's where data orchestration steps in. It ensures the data flows constantly, arriving at the right time with the correct order. For this task, Apache Airflow, Dagster, and Prefect are popular solutions.
7) Data Governance : Data governance is all about decision-making. Specifically, deciding how data should be dealt with in terms of availability, usability, and security. It's more than just a SaaS Solution—it's a combination of people, processes, and principles to set and upkeep standards, manage data visibility, and foster compliance. Questions arise, how such practices are sustained in organizations? The answer lies in the effective use of data catalog solutions.
8) Data Catalog : A Data Catalog is, in essence, a data platform’s encyclopedia. It uses the metadata to provide descriptive information on critical data assets. Wondering how it helps? It supports compliance use cases as a part of data governance processes. Moreover, it provides real-time access to reliable data.
9) Data Discovery : As the name signifies, data discovery empowers data teams to trust that their assumptions about data match the reality—essentially a navigation system updated with the latest insights and information. It's this layer of the data platform that evolves as data becomes increasingly complex.
10) The Semantic Layer : Don't confuse it with music layer; a semantic layer helps define and secure the aggregated metrics significant to business operations. This single source of truth allows businesses to work towards shared goals, thanks to the unification of key metrics calculations. Looker and LookML pioneered this, and now it's becoming an integral part of the modern data platform, thanks to dbt.
11) Access Management : It's all about protecting sensitive and private information and thwarting fines from regulations like GDPR or CCPA. Ever heard of Immuta, BigID, Privacera, Okera, and SatoriCyber? These are some vendors offering state-of-the-art access management solutions.
12) Machine Learning and Generative AI : The world is obsessed with how AI might replace our jobs, but the good news is, it's not happening anytime soon. Instead, AI-based solutions like GitHub Co-Pilot, Snowflake Document AI, and Databricks LakehouseIQ are all about increasing productivity.
A modern data platform typically consists of multiple, integrated cloud-based solutions, with a data warehouse or lakehouse at the center for storage and processing. Other common components like ingestion, orchestration, transformation, business intelligence, and data observability play critical roles in data management and analytics. Data orchestration, data governance, catalog, discovery, semantic layer, and access management form the backbone of a robust data stack. And when you add Machine Learning and Generative AI to the mix, you have a recipe for success.

.jpg)
.jpg)
.jpg)


.jpg)



.jpg)