Data engineering is an essential aspect of any organization that deals with large volumes of data. It involves collecting, transforming, and delivering data to provide valuable insights for decision-making. To efficiently carry out these tasks, data engineers rely on various tools and technologies.
Tableau is a powerful data visualization tool that allows users to easily analyze and understand data through interactive dashboards and reports. With Tableau, data engineers can connect to various data sources, perform data transformations, and create visually appealing visualizations.
Use case: Data engineers can use Tableau to visualize complex data sets, create interactive dashboards for business intelligence, and generate insightful reports for data-driven decision-making.
Snowflake is a cloud-based data warehousing platform that offers a fully managed and scalable solution for storing and analyzing large volumes of data. It provides the flexibility to handle diverse data types and support multiple workloads simultaneously.
Use case: Data engineers can leverage Snowflake to build a centralized data warehouse, perform complex analytics, and enable seamless data sharing across different departments within an organization.
Redshift is a fully managed data warehousing solution provided by Amazon Web Services (AWS). It is designed to handle large-scale data analytics workloads efficiently, providing high-performance query execution and scalability.
Use case: Data engineers can utilize Redshift to build data warehouses that enable fast and cost-effective analysis of large data sets, enabling organizations to derive valuable insights and make data-driven decisions.
BigQuery, part of Google Cloud Platform (GCP), is a serverless data warehousing solution that offers real-time analytics and data exploration capabilities. It allows users to analyze large datasets quickly and efficiently.
Use case: Data engineers can leverage BigQuery to process and analyze massive amounts of data in real-time, enabling organizations to gain valuable insights and improve decision-making processes.
Hadoop is an open-source framework that allows for the distributed processing of large datasets across clusters of computers. It provides fault-tolerance, scalability, and the ability to process unstructured data effectively.
Use case: Data engineers can use Hadoop for data preprocessing, large-scale data analysis, and extracting actionable insights from unstructured data sources like social media, logs, and sensor data.
Apache Spark is a fast and general-purpose data processing engine that supports in-memory data processing, enabling real-time analytics and iterative algorithms. It offers high-level APIs in Java, Scala, Python, and R.
Use case: Data engineers can utilize Spark for processing large volumes of data in real-time, running machine learning algorithms, and performing graph processing for complex data analysis tasks.
Apache Airflow is an open-source platform used for workflow management and orchestration. It allows data engineers to define, schedule, and monitor data pipelines, ensuring the smooth execution of data-related tasks.
Use case: Data engineers can use Airflow to automate data pipelines, schedule and monitor data transformations, and ensure reliable data delivery across different systems within an organization.
Data Build Tool is a lightweight and flexible data pipeline creation tool. It enables data engineers to define data transformation steps and dependencies, making it easier to create and manage data pipelines.
Use case: Data engineers can leverage Data Build Tool to automate the process of building data pipelines, ensuring data consistency, quality, and efficient delivery.
Fivetran is a cloud-based data integration platform that enables easy extraction, transformation, and loading (ETL) of data from various sources into a data warehouse.
Use case: Data engineers can use Fivetran to streamline the process of data integration, eliminating the need for manual data extraction and transformation, and enabling faster and more accurate data delivery.
Looker is a powerful business intelligence platform that enables users to explore and analyze data through interactive dashboards and reports. It provides a user-friendly interface for data exploration and visualization.
Use case: Data engineers can use Looker to build interactive dashboards and reports, enabling business users to explore data and gain valuable insights for decision-making processes.
Data engineering tools play a crucial role in handling large volumes of data efficiently. Tableau, Snowflake, Redshift, BigQuery, Hadoop, Spark, Airflow, Data Build Tool, Fivetran, and Looker are some popular tools that data engineers rely on to collect, transform, and deliver data to enable organizations to make data-driven decisions. Each tool has its specific use cases, ensuring seamless data processing, analysis, visualization, and workflow management at scale.








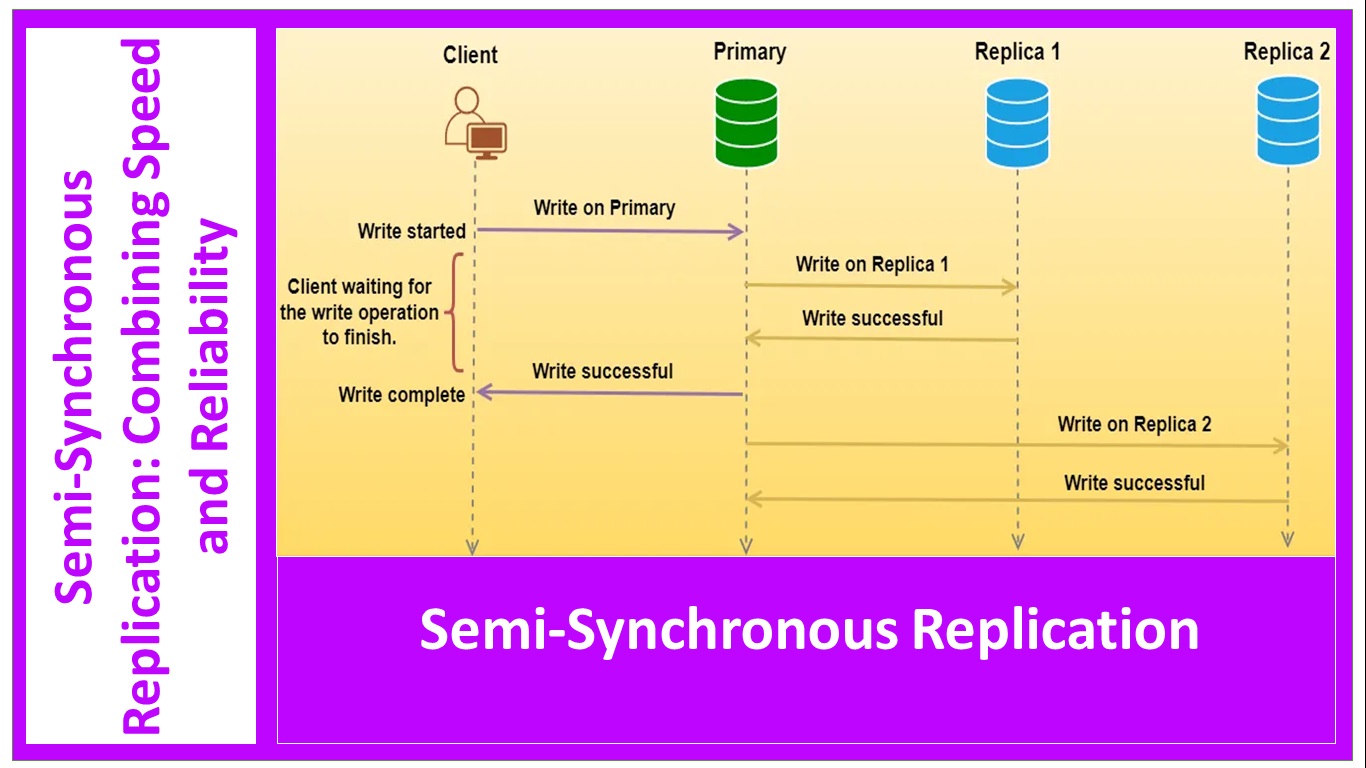

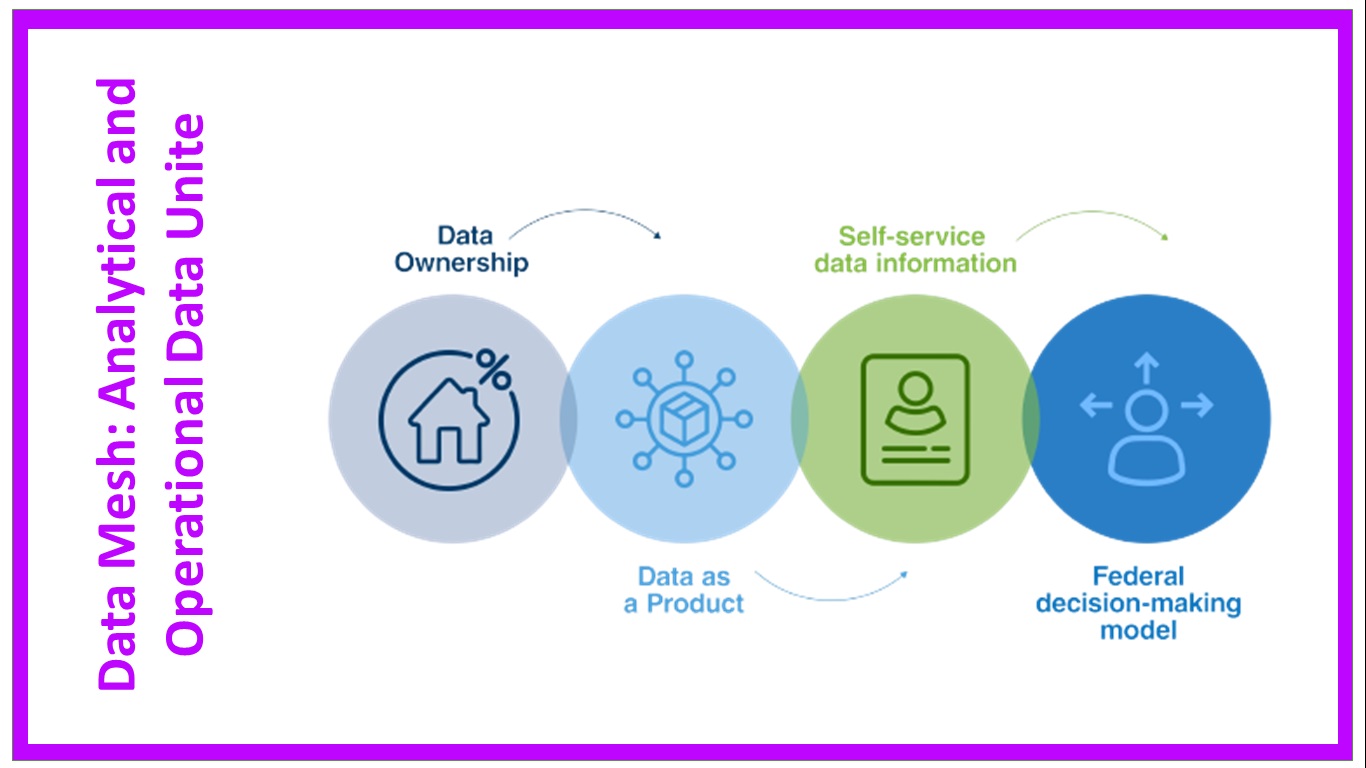
.jpg)